Comparing Standard Recurrent Neural Network and Long Short-Term Memory Neural Network on Char-RNN
Author: Maya Que
The paper can be viewed on this page.
Abstract
This study investigates the efficacy of standard Recurrent Neural Networks (RNNs) versus Long Short-Term Memory (LSTM) networks through the Char-RNN model. A dataset comprising texts from the Sherlock Holmes series was used, and two sets of Char-RNN models were trained using either a standard RNN or LSTM architecture. The comparative analysis focused on average loss across three trials over 20,000 training iterations for each model. Furthermore, the quality of the generated text was evaluated to assess the model performance. Results show that LSTM networks significantly enhance learning efficiency compared to standard RNNs, with the text generated by LSTM networks showing superior quality.
Introduction
The Char-RNN model, as discussed by Karpathy in “The Unreasonable Effectiveness of Recurrent Neural Networks” [1], presents an effective approach to the language model by operating at the character level to generate coherent and contextually relevant text. Unlike traditional word-level models, Char-RNN processes text at the granularity of individual characters, which allows it to capture more fine-grained patterns and nuances and generate text with a high degree of flexibility. Char-RNN is implemented using a recurrent neural network (RNN), a class of artificial neural networks for modeling sequential data. Whereas standard neural networks assume fixed length input and output, RNN processes input sequences of variable lengths by maintaining a hidden state that retains information from previous time steps. This recurrent nature gives RNNs the ability to capture temporal dependencies and long-range contextual information, making them suitable for tasks involving sequential data like language modeling. Figure 1 shows examples of how RNN operates over sequences of vectors in the input, output, or both.
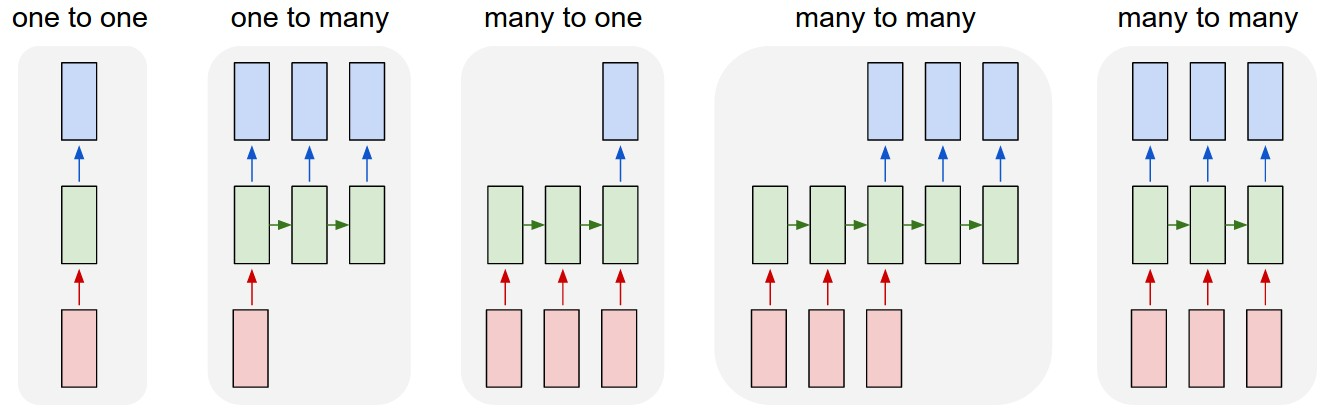 Figure 1. Sequences of Vectors [1]
Figure 1. Sequences of Vectors [1]
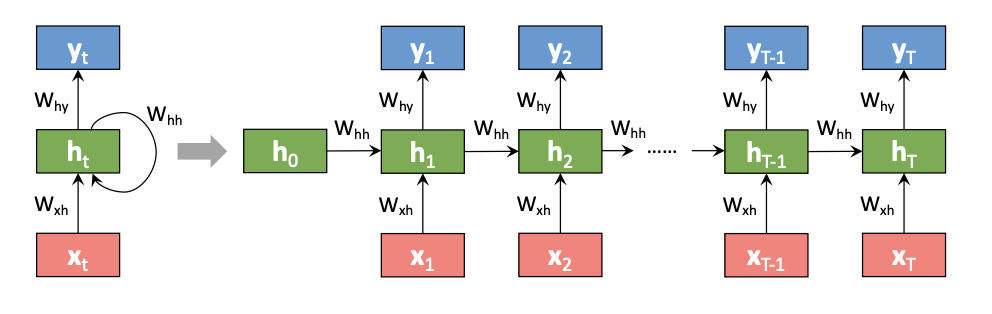 Figure 2. A Standard RNN
Figure 2. A Standard RNN
The structure of a standard recurrent neural network can be represented through mathematical equations. On the forward pass, the hidden state $h^{(t)}$ at each step $t$ is calculated using the following equation:
\[h^{(t)} = \sigma(W^{hx}x^{(t)} + W^{hh}h^{(t-1)} + b_{h)}\]Here, $x^{(t)}$ represents the input at time step $t$, $W^{hx}$ represents the weight matrix connecting the input to the hidden layer, $W^{hh}$ represents the weights for the recurrent connections, $b_{h}$ is the bias term, and $\sigma$ represents the activation function, commonly the sigmoid or hyperbolic tangent function. The hidden state $h^{(t)}$ is computed by combining information from the current input $x^{(t)}$ with the previous hidden state $h^{(t-1)}$, which enables the network to capture temporal dependencies and context.
Furthermore, the prediction $\hat y^{(t)}$ at time t is given by the application of a softmax function to the weighted sum of the current hidden state:
\[\hat y^{(t)} = softmax(W^{yh}h{(t)} + b_y)\]In this equation, $W^{yh}$ denotes the weight matrix connecting the hidden state to the output layer, and $b_y$ represents the bias term. The hidden state is computed using both the input $x^{(t)}$ and the previous hidden state $h^{(t-1)}$, which allows recurrent neural networks to make predictions based on sequential information.
However, despite their efficacy, traditional RNNs suffer from certain limitations such as difficulty in learning and retaining information over sequences of considerable length where information from distant time steps becomes effectively inaccessible. This issue, commonly referred to as the “vanishing gradient” problem, arises due to the diminishing impact of gradients during backpropagation, which causes gradients to diminish exponentially over time, hindering the network’s ability to propagate information and learn long-term dependencies. To address these challenges, Long Short Term Memory (LSTM) networks are introduced. LSTM networks offer a solution to the vanishing gradient problem by incorporating specialized memory cells that are capable of retaining information over multiple time steps. Through a system of gated units that enables them to store and retrieve information over multiple time steps, LSTM networks selectively update and forget information over extended time horizons, facilitating more robust and efficient learning of long-range dependencies.
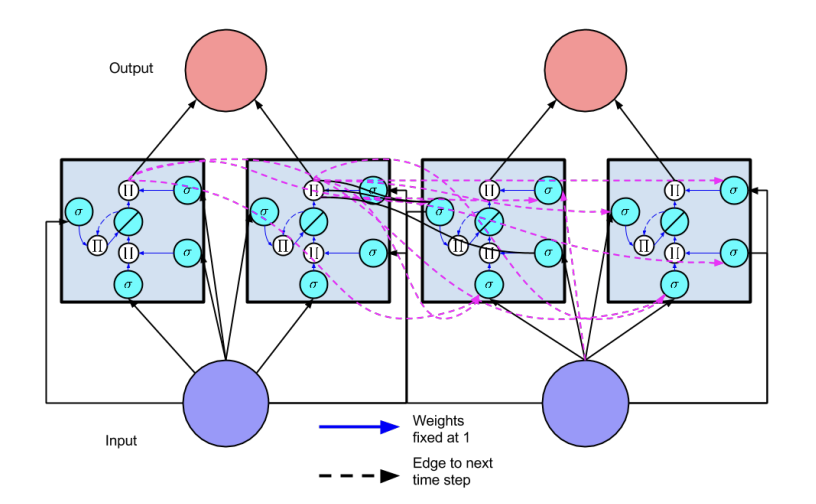 Figure 3. A LSTM (Full Network)
Figure 3. A LSTM (Full Network)
Although the LSTM network stands out for its ability to capture long-term dependencies in sequential data, the effectiveness of LSTMs compared to standard RNNs in tasks like text generation can be further investigated. This study aims to examine and compare the performance of standard RNN models with LSTM models within the context of the Char-RNN framework. Experiments will be conducted to assess the effectiveness of both architectures in terms of learning efficiency and text generation quality. By comparing the strengths and weaknesses of each model, this study aims to contribute to a deeper understanding of their applicability in language modeling tasks.
Method
The dataset used comprises the complete works of Sherlock Holmes by Conan Doyle. After removing nonprintable characters, the dataset consisted of 3,381,831 characters. It also includes 100 distinct characters, including numerical digits, lowercase and uppercase letters, and special characters.
The basic implementation of the model was taken from the skeleton code provided in Homework 5 RNN. Two variants of recurrent neural networks, namely the standard RNN and Long Short-Term Memory (LSTM) networks were employed in this study. The models were implemented using RNNCell and LSTMCell classes available in the PyTorch torch.nn package. Both models utilized a cross-entropy loss function to compute training loss.
Three independent trials, each involving a distinct network, were conducted for both the standard RNN and LSTM architecture. Each trial consisted of 20,000 training iterations. During training, losses were recorded at intervals of 100 iterations. The recorded losses were subsequently averaged across the three trials for each model. This averaging process was then used to obtain representative measures of training loss. The primary evaluation metric employed in this study was the training loss, which served as an indicator of the model’s learning efficiency. Additionally, the quality of the text generated by each model was assessed qualitatively to gauge the effectiveness of the generated output. Using this, hyperparameters were tuned on the better model and trained again on 50,000 iterations to observe the final generated text output.
Experiment
The experiment aimed to compare the performance of standard Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) networks within the context of the Char-RNN model. Specifically, the study sought to investigate whether the LSTM architecture, known for its ability to mitigate the vanishing gradient problem inherent in RNNs, would yield superior performance in terms of learning efficiency and text generation quality.
The null hypothesis is that there would be no significant difference between the training loss curves for the RNN model and the LSTM model. However, based on the known challenges of vanishing gradients in RNNs and the more sophisticated design of LSTM networks, it was hypothesized that the LSTM model would outperform the standard RNN model in terms of learning efficiency and quality of generated text.
| Iterations | Standard RNN | LSTM |
|---|---|---|
| 1 | 3.015 | 3.077 |
| 5000 | 1.786 | 1.586 |
| 10000 | 1.708 | 1 |
| 15000 | 1.732 | 1.481 |
| 20000 | 1.692 | 1.396 |
Table 1. Loss averaged across 3 trials over 20,000 training iterations for RNN and LSTM models
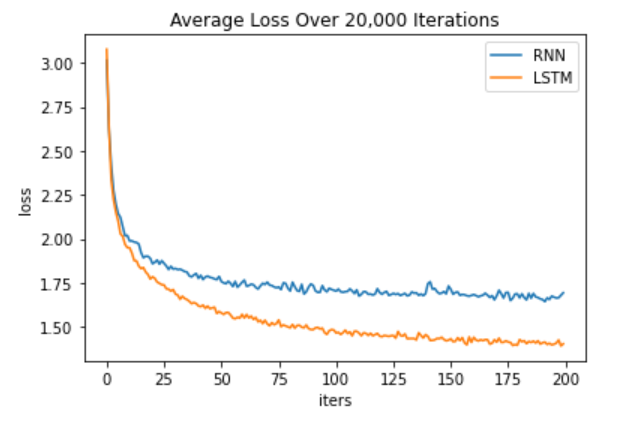
Figure 4. Average loss across 3 trials over 20,000 training iterations for RNN and LSTM models (number of iterations shown in hundreds)
The experiment’s results revealed a significant difference in the training loss curves between the RNN and LSTM models. The LSTM model exhibited a faster rate of decrease in average loss compared to the RNN model. Additionally, qualitative analysis of the generated text demonstrated that the LSTM model produced text with fewer errors and a more coherent structure compared to the RNN model. These findings support the hypothesis that the LSTM model outperforms the standard RNN model in terms of learning efficiency and text generation quality.
Text generated by standard RNN model:
Wat busk the deeplequre again mysiact pit and a polits a man of very a didie six caskied go ame the kind and as of the fardd. This in that A compan womnd at the case of dork since sir an it tried a commanch. Chey, right I ar women have make did stain day kno sem. He, a most that a tall besred makered a train, I should st and you manng a greforamplation markwhign rish a takemente you swopl a liph. ligk. Dr reascenwards in the that yay’s stopes as the siinly shaursely he man with mishedon help. It’ for the Amaht not carded jagg the track so handlr at sme us, the diich hely ac
From the text generated by the RNN model, one can see that it is not that coherent and difficult to distinguish real words.
Text generated by LSTM model:
We bilms mayer was a find lieked daver to wilary; in the most carried. Gear out of the broom Llet ingool the party was would see why that off odent side, but to hear with like beside. The clay before was never studged. What eaken?’ I realy or a besturans, came how davento. Prink why that’s carried observed a small face, bruther and Englan, and the trank after a dounged ocefien Saw there did we working afa boosy, one, that you have bond. I have mannow brought in difend into the bond my addertifully, ale and who was messable from Housary oll at t
In comparison, the text generated by the LSTM model demonstrates a higher degree of coherence, resembling real sentences and showing fewer spelling errors and nonexistent words. While both texts may not be fully interpretable still, the LSTM generated text shows more promise in capturing the nuances in Sherlock Holmes stories with more recognizable keywords associated with mystery novels.
The LSTM model was tuned for hyperparameters using various combinations of learning rates, hidden sizes, and batch sizes. After evaluating all the combinations, the hyperparameters that yielded the best performance was selected to train the LSTM model again on the training set for 50,000 total iterations. The text generated by the final LSTM model is shown below.
Within the spoke upon all week. “And he be a pennies. “The matter and pattered by give used to answered, and, might showed all to trut which had went them. I was night, the points is not first I saw man, and his shut clusch for he may never introg regasion. I wiger its. I saw anot, apperitually turned in the room, and a king the time, in those cry of that these last a matter to be can well 6zed these terrible or at the trust are away that I bake Lestrade, that his untalution own unounse Stay handing Booker fact on the house is seven re obsers in his safe
The text shows continued improvement that shows a progression in forming narratives similar to the original style of Sherlock Holmes with the incorporation of formatting that is also reminiscent of a novel.
Conclusion
This study provides insight into the effectiveness of different recurrent neural network variants for language modelling tasks through comparing the performance of standard Recurrent Neural Networks (RNN) with Long Short-Term Memory (LSTM) networks within the Char-RNN model framework. A significant difference in the training loss curves was observed between the RNN and LSTM models over 20,000 training iterations. The LSTM architecture exhibited a notably faster rate of decrease in average loss compared to the standard RNN model. This underscores the effectiveness of LSTM networks in addressing the challenges associated with vanishing gradients in traditional RNNs, leading to more efficient learning. Qualitative assessment of the text generated by the model further supported the quantitative findings. The LSTM model produced text with fewer errors, a more coherent structure, and a greater resemblance to the original style of Sherlock Holmes text, demonstrating its superior performance in text generation tasks. In contrast, the text generated by the standard RNN model exhibited more spelling errors, non-existent words, and irregular punctuation usage. Overall, these findings support the hypothesis that LSTM networks outperform standard RNNs in the context of Char-RNN for language modeling tasks.
However, several limitations should also be acknowledged. This study focused on a specific dataset, so the findings may not be generalizable to other domains and applications. Additionally, due to limited computational resources, only three trials were conducted with 20,000 iterations for each trial. Having more trials will help make a more statistically conclusive finding about the performance of these two models. The experiment also did not explore a fully comprehensive range of hyperparameters or model configurations. Other implementations of this study can do so to see how they influence the performance of the architecture.
This study can provide valuable insights and potential applications into the field of natural language processing and neural network design. The observed improvements of LSTM networks over standard RNNs in terms of learning efficiency and text generation quality highlight the importance of using an architecture that is capable of addressing long-range dependencies in sequential data. Future research can explore further enhancements to LSTM-based models, such as incorporating attention mechanisms or exploring different cell architectures to optimize performance. This can also have implications for other downstream applications, including language translation, sentiment analysis, and dialogue generation. By identifying the relative strengths and weaknesses of these models, this study contributes to laying the groundwork for future advancements in neural network-based language modeling.
Reference
[1] Karpathy, A. (2015). The Unreasonable Effectiveness of Recurrent Neural Networks. Andrej Karpathy blog. http://karpathy.github.io/2015/05/21/rnn-effectiveness/
[2] Doyle, C. The complete Sherlock Holmes. https://sherlock-holm.es/stories/plain-text/cnus.txt
[3] Tu, Z. (2024, March 22). Lecture 14: Recurrent Neural Networks [Lecture notes]. COGS 181, Winter 2023 Neural Networks and Deep Learning, University of California, San Diego.
[5] Tu, Z. (2024). Homework Assignment 5 RNN. COGS 181, Winter 2023 Neural Networks and Deep Learning, University of California, San Diego.